MixDir: Scalable Bayesian Clustering for High-Dimensional Categorical Data
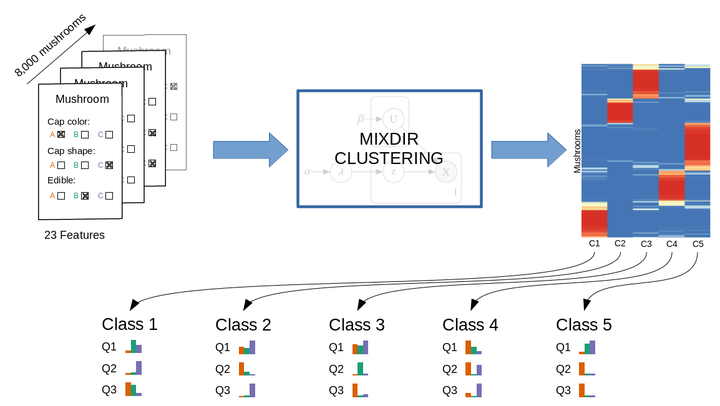 mixdir overview
mixdir overview
Abstract
Multivariate analysis of high-dimensional datasets with multiple categorical variables (e.g. surveys, questionnaires) is a challenging task but can reveal patterns of responses that are masked from univariate analyses. In this paper we propose a novel variational inference algorithm to cluster high-dimensional categorical observations into latent classes. Variational inference is an approximate Bayesian inference algorithm, which combines fast optimization methods with the ability to propagate the uncertainty to the clustering (soft clustering). The model is robust to misspecification of the number of latent classes and can infer a reasonable number from the data. We assess the performance on synthetic and real world data and show that our algorithm has similar performance to the best other tested method if the correct number of classes is known and outperforms the other methods if it the number of classes needs to be inferred. An R-package implementing our algorithm is available at the Comprehensive R Archive Network.